It was 10:03 am, EST. My wife called: all their applications at work were down. They were worried as her company had completed their cloud migration to ‘DRT Cloud’ a few weeks earlier. No feedback from the cloud provider support, though.
I switched on my TV and lost my breath: “BREAKING NEWS - CLOUD PROVIDER DRT CLOUD WENT OUT OF SERVICE IN NORTH & SOUTH AMERICA AND EUROPE. RECOVERY TIME IS UNPREDICTABLE, COMPANY SAYS.”
How could that be possible? After years and billions of infrastructure investments worldwide!!
The day after, DRT Cloud clarified his network links went out of service, due to a major earthquake undersea. Service might remain unavailable for weeks…
An hour later, stock exchanges worldwide were falling.
‘DRT Cloud’ is a fiction name I decided to use, maybe being a little superstitious…
Could the above scenario happen in the real world?
It’s rather unlikely.
Cloud providers have invested in reliable infrastructure and redundant network connections worldwide.
There are threats, but the global scale is itself the best mitigating factor.
HOW MAJOR CLOUD PROVIDERS BUILT GLOBAL INFRASTRUCTURES AND NETWORKS
AWS, Google Cloud and Microsoft Azure built a global infrastructure, with regions deployed worldwide, connected by resilient and performant network.
Regions redundancy isn’t always ensured at the Continent level though, meaning resilience to regional disaster can be challenging.
Let’s give a closer look.
AWS
AWS Global Infrastructure is made up of regions, designed to be isolated from each other and deployed worldwide.
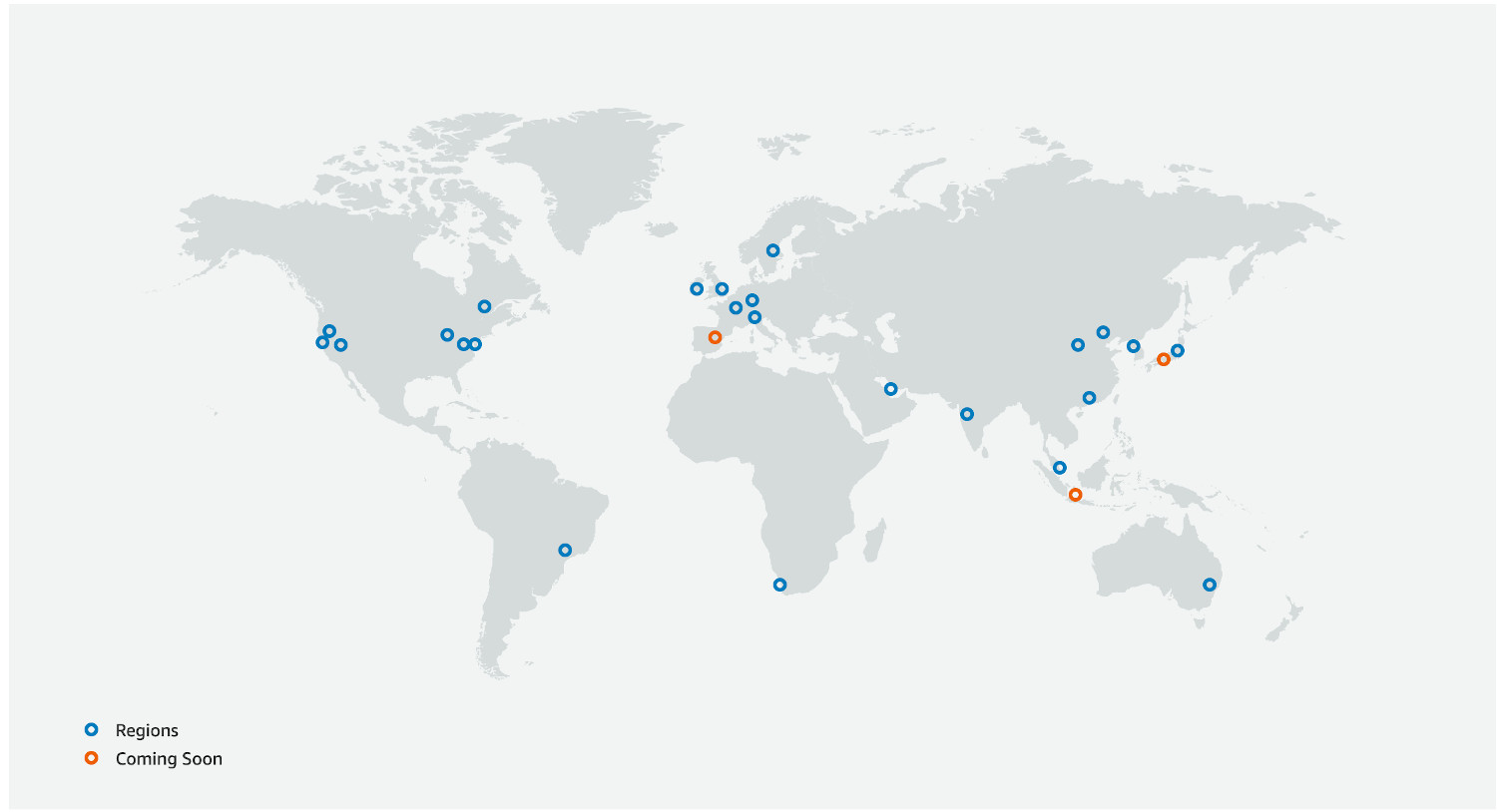
All regions have availability zones, which ensures isolation within a region
AWS global network is a fully redundant 100 GbE fiber network backbone, circling the world via trans-oceanic cables, often providing many terabits of capacity between Regions
AWS builds its own chips, servers, routers, storage, and load-balancers, to ensure the fastest path of innovation, standardization, and the highest levels of reliability.
I recommend to visit the interactive AWS infrastructure page.
Google Cloud
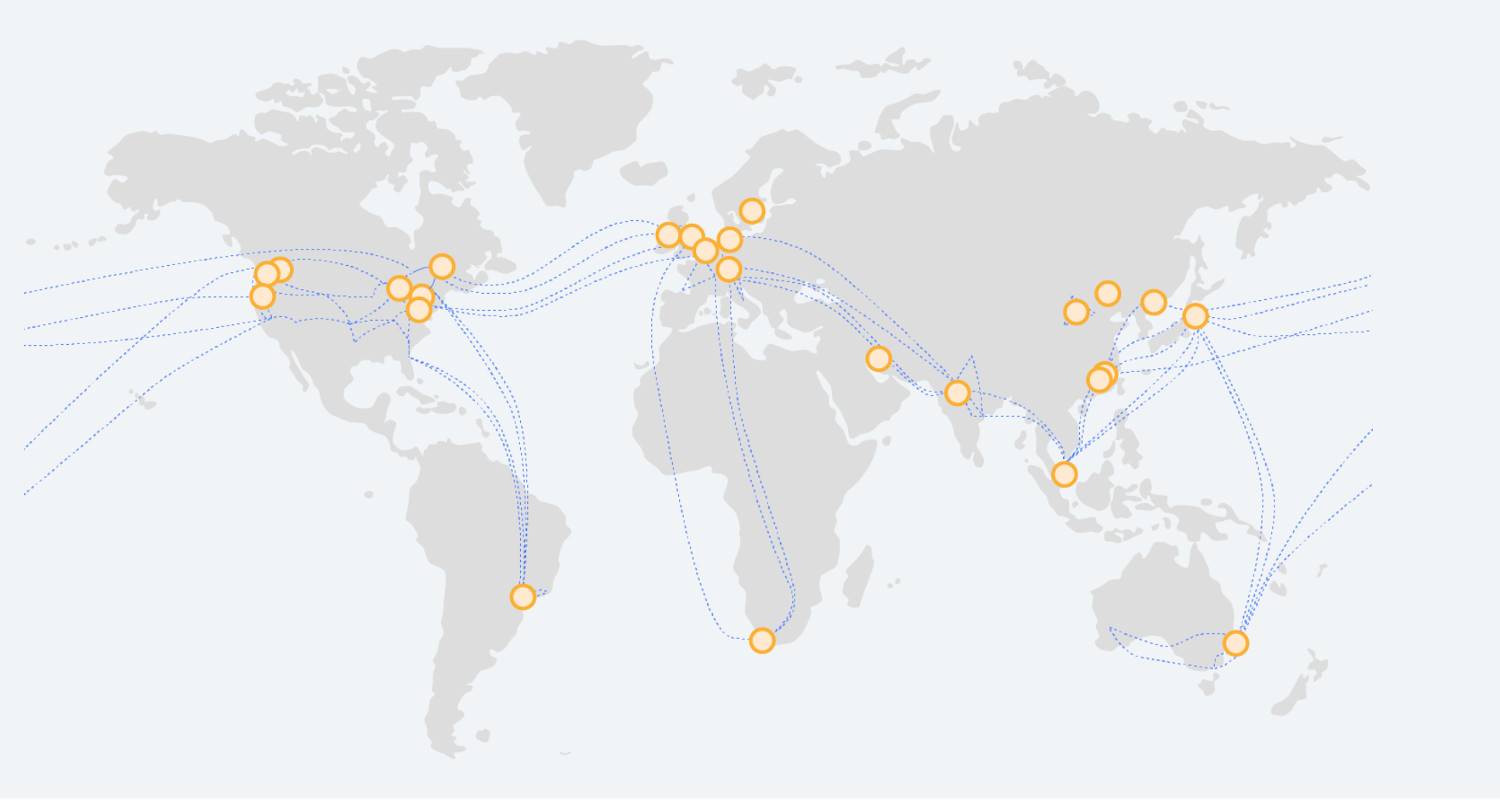
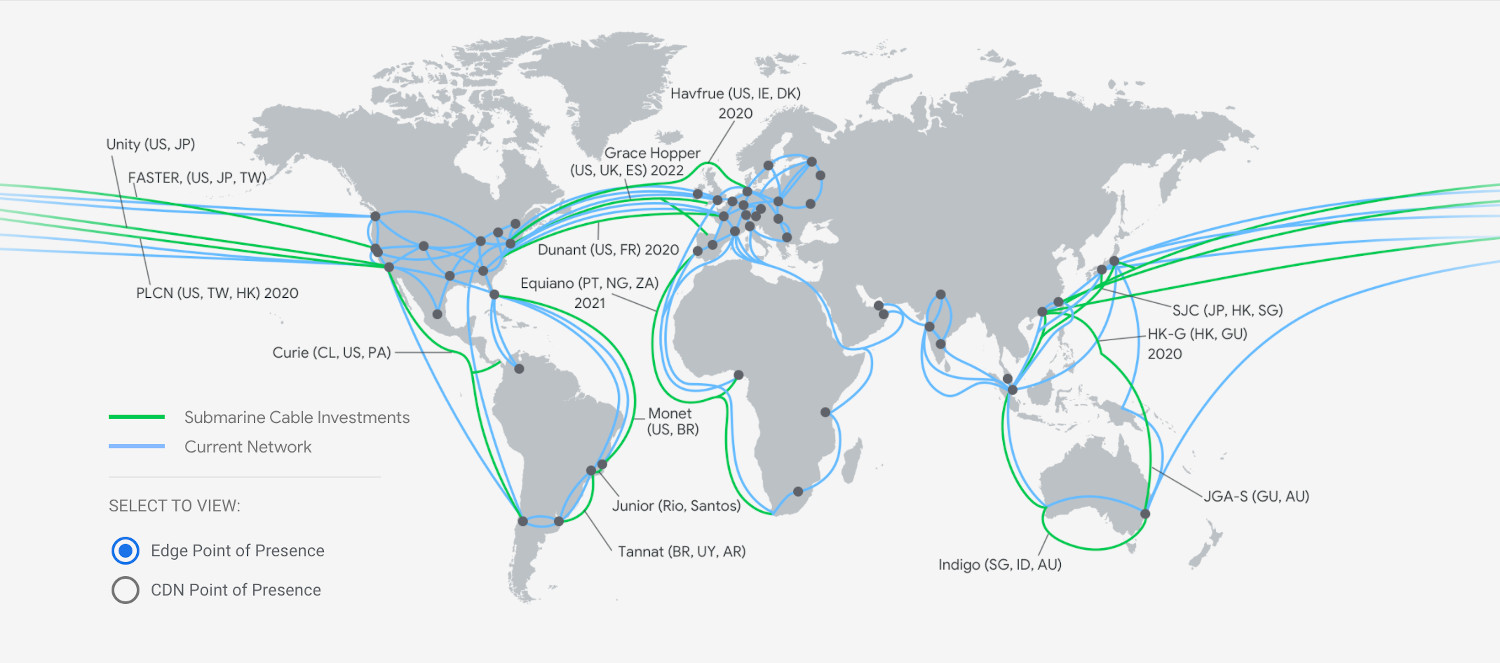
Google Cloud global infrastructure is deployed worldwide.
Google is the largest owner and investor in submarine cable networks globally.
I recommend exploring the interactive Google global infrastructure website.
Microsoft Azure
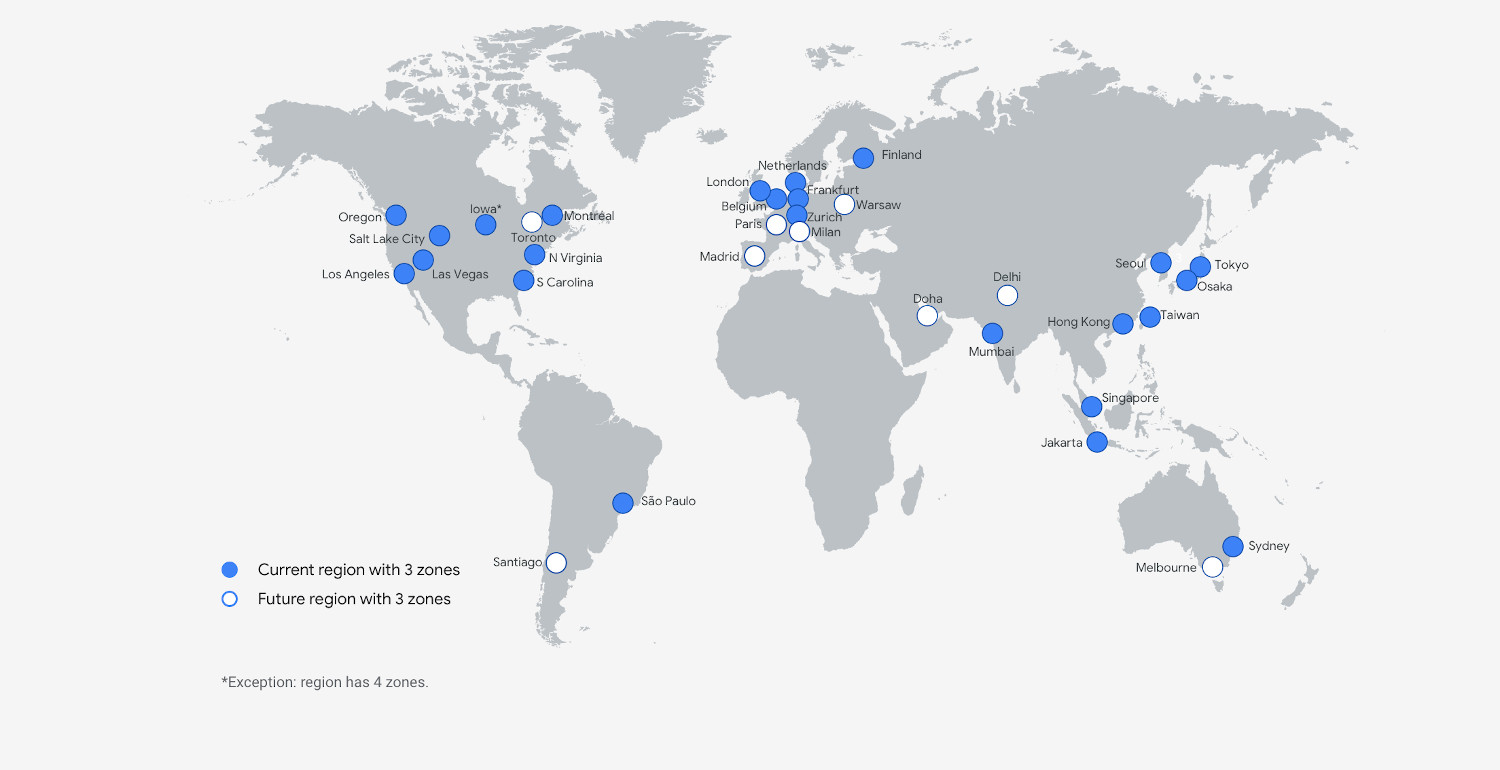
Azure Global Infrastructure is deployed worldwide.
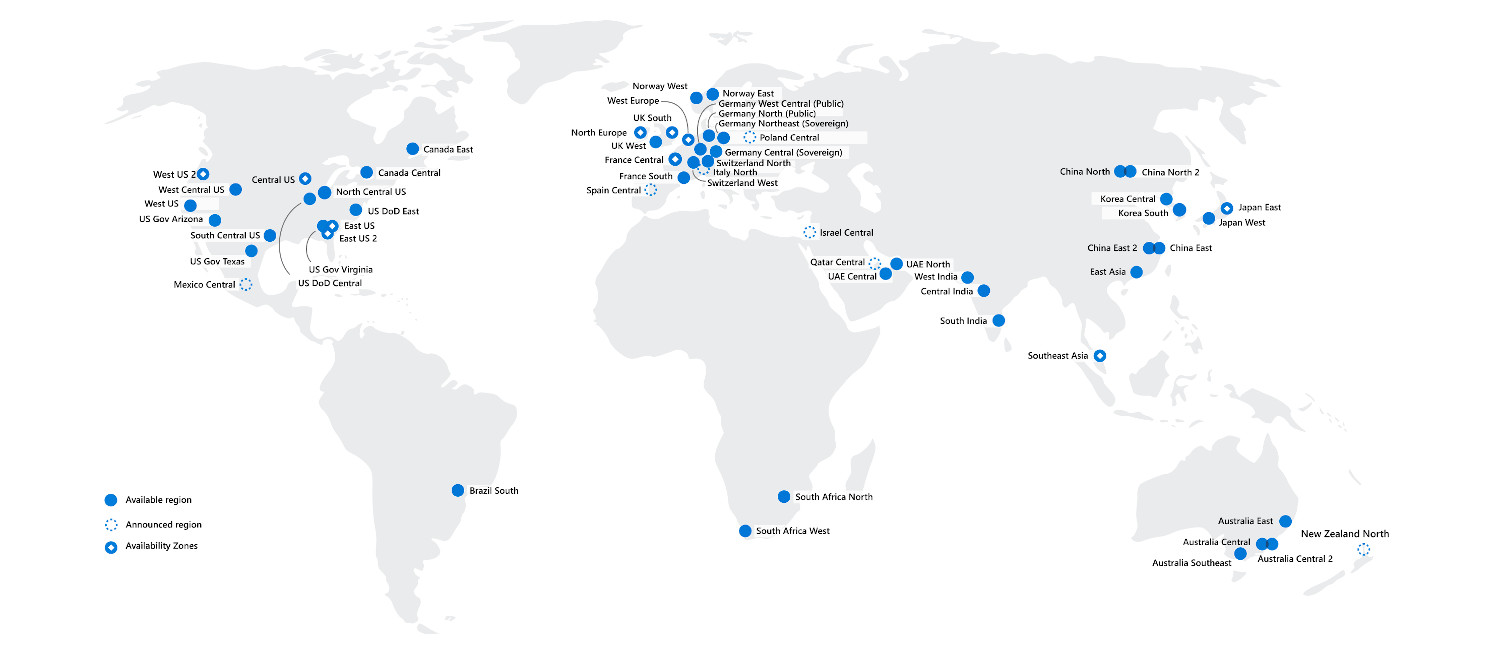
Azure Global Network is one of the largest networks in the world.
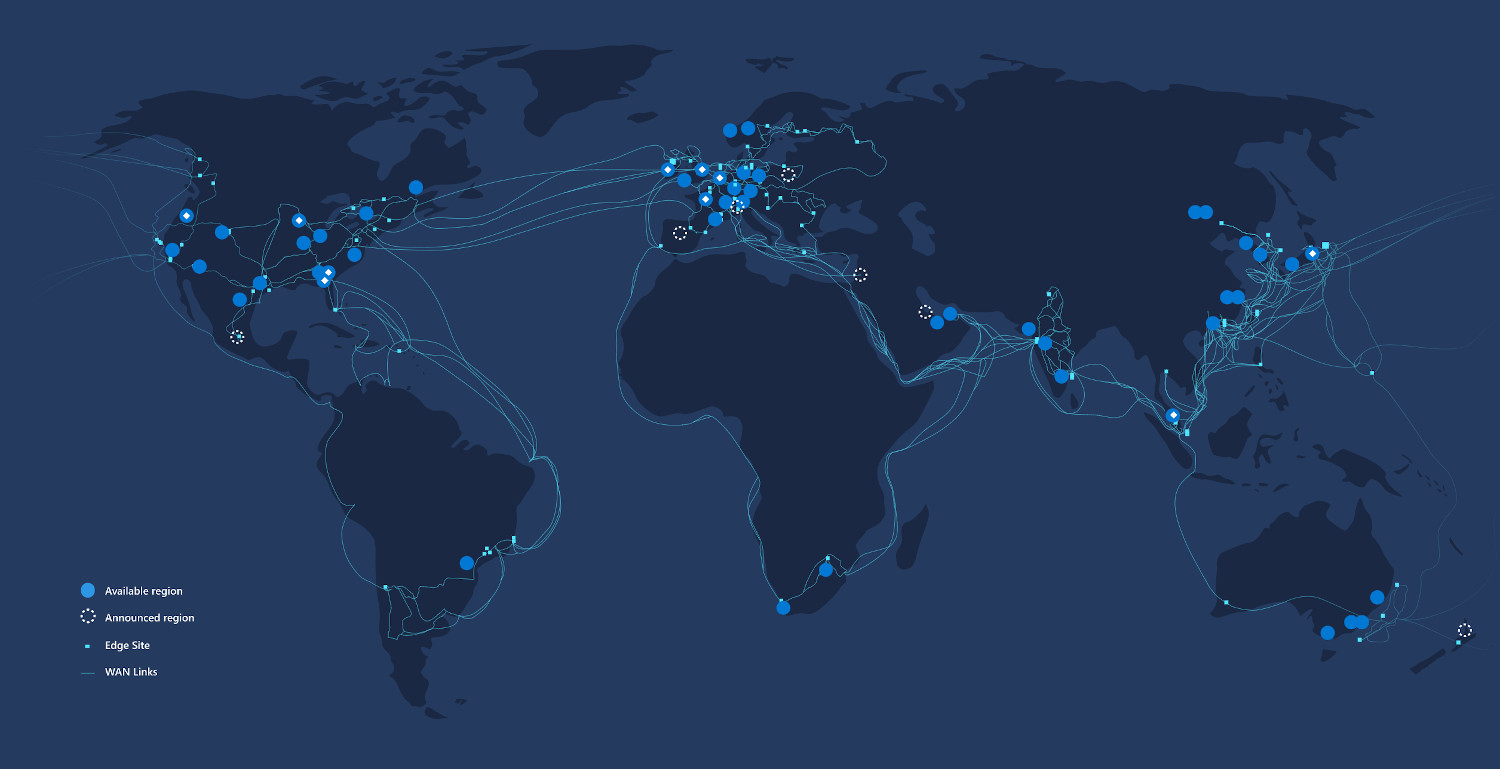 Microsoft Azure Global Network
Microsoft Azure Global Network
Also, Microsoft is strongly supporting open source hardware innovation.
IMPRESSIVE RIGHT? BUT ARE CLOUD PROVIDERS SERVICES IMMUNE FROM OUTAGES?
 Photo by Andrew Coop on Unsplash
Photo by Andrew Coop on Unsplash
Well, not at all.
Major outages happened, taking down one or more regions for a significant time.
Let’s look at some of the major ones in recent times:
-
Wednesday, April 8, 2020: an issue with Identity and Access Management service at Google Cloud caused severe service outage for about an hour
-
March 24-26, 2020: Azure VM capacity constraints arising from the global health pandemic affected many customers in Europe and the United Kingdom
-
Sunday, January 23, 2020: AWS suffered a 7.5 hour region-wide outage of the VPC subsystem in the ap-southeast-2 (Sydney)
-
Monday, November 11, 2019: an issue with Key Management System at Google Cloud impacted many services in two US regions and one region in South America for more than 2 hours
-
August 31, 2019, AWS US-EAST-1 datacenter in North Virginia faced terrible power failure leading to failure of the datacenter’s backup generators. It led to 7.5% of the EBS volumes and EC2 instances becoming unavailable. After the restoration of power, Amazon determined that some of them had incurred hardware damage with loss of data. Some customers faced extensive data loss questioning the security of the data stored in the cloud
-
Sunday, July 2, 2019: a Google Cloud network outage affected YouTube, Gmail, and Google Cloud users like Snapchat and Vimeo, disrupting services for up to four and a half hours
-
September 2018, November 2018 and May 2019: 3 major Azure cloud failures. A data center outage in the South Central US region in September 2018, Azure Active Directory (Azure AD) Multi-Factor Authentication (MFA) challenges in November 2018, and DNS maintenance issues in May 2019
-
Friday, March 2, 2018: a power outage hit the AWS-East Region (Ashburn), affecting hundreds of critical enterprise services like Atlassian, Slack and Twilio. Significant corporate websites and Amazon’s own service offerings were impacted as well
-
Tuesday, February 28, 2017, the US-East-1 region of Amazon Web Services S3 saw a complete outage from 9:40am to 12:36pm PST. Besides, many other AWS services that depend on S3 — Elastic Load Balancers, Redshift data warehouse, Relational Database Service, and others — also had limited to no functionality.
Summarizing:
- outages happen
- impacts can be bigger than expected since a growing ecosystem of service partners moved their services to the cloud
- communication and transparency might be a challenge during outages.
Here are the links to real-time status pages for AWS, Google Cloud and Microsoft Azure.
CLOUD REPATRIATION: ARE COMPANIES MOVING AWAY FROM THE CLOUD?
 Photo by Ashwini Chaudhary on Unsplash
Photo by Ashwini Chaudhary on Unsplash
Cloud repatriation is happening, meaning “the shift of workloads from public cloud to local infrastructure environments, typically either a private or hybrid cloud environment”.
This is happening for several reasons, such as:
- poor initial planning, which brought to unexpected issues or outcomes below expectations;
- unexpected costs, storage for instance, or compliance issues, often for data
- security issues or worries
- insufficient operational readiness.
Repatriation can also be a “move forward” though, entailing a migration to more sophisticated types of cloud-based architectures.
For example, leveraging “cloud at customer” solutions, such as AWS Outpost, Azure Stack or Google Cloud Anthos, can ease compliance constraints while leveraging a full cloud model.
CONCLUSIONS: CLOUD PROVIDERS BUILT GLOBAL INFRASTRUCTURE AND SERVICES, BUT MAJOR OUTAGES HAPPEN, COMPANIES ARE MOVING BACK TO ON-PREM…SHOULD YOU REALLY START YOUR CLOUD JOURNEY? SURE! RIGHT NOW!
 Photo by Karsten Wurth on Unsplash
Photo by Karsten Wurth on Unsplash
My point is that embracing the cloud brings huge benefits, but comes with challenges and risks which need to be properly understood and mitigated.
Cloud providers let your IT organization access global scale, consumption service models, built-in security and compliance, continuous innovation, growing service options with decreasing costs.
Thus, time to market, modernization, and transformation programs can be significantly accelerated, but cloud adoption has to be matched with a strong program to build enabling capabilities, at infrastructure, architectural, and application development levels.
There are trade-offs: complexity, costs control, performance, operational readiness, lock-in, skills, just to mention a few.
You can prepare and experiment, starting a wise and learning journey to bring immediate value, while mitigating risks and ensuring proper learning.
Here are my recommendations, based on my experience and what I’ve learned so far:
- select one or two cloud providers first, specializing their usage (IaaS, DB PaaS, ML for instance); cloud selection might be driven by existing contracts agreements (such as license agreements), to save costs and speed-up adoption and learning
- understand cloud service models, through low-risk POCs and training
- define basic use-cases, starting low and easy: labs, IT platforms, non-productive environments, low critical applications front ends lift and shift, cross-services adoption, such as IAM
- plan and design resilience and performance, for infrastructure (regions, zones, network) and up to architecture and applications layers; don’t forget proper management practices
- ensure security solutions (vulnerability and security events management at least) and related processes (who is going to manage security events and incident response)
- adapt and ensure compliance with your company’s business continuity and disaster recovery scenarios
- ensure data compliance and resilience (back-up in different locations, maybe on-prem)
- build basic costs control processes (spending per service, alerts, optimization opportunities)
- invest in capabilities to automate and foster cloud opportunities, such as infrastructure abstraction, and Hybrid and multi-cloud solutions
- define your exit strategy, enabled by the above elements, and required by many regulations worldwide.
While starting your “wise journey”, you can fill your IT Cloud Strategy, for instance by setting the path to relevant workloads migration of building cloud-native ones. All steps above will help you get to a clearer picture of how to proceed further.
“I am not afraid of storms, for I am learning how to sail my ship.”
Louisa May Alcott, Little Women
(Photo on top by Jeremy Thomas on Unsplash)